概述
在没有 js 引擎之前, 都是没有编译的, 浏览器作为解释器对运行到的每条语句进行解释, 这样会导致 js 运行十分的慢, 一旦遇到比较复杂的逻辑, 解释再运行会消耗大量的时间, 加上 js 的单线程运行时, 就会阻塞后续的代码执行, 更无法响应用户的交互. 所以在没有引擎之前的前端, js 代码很少, 那会前端被称为切图工程师, 只需要制作出静态的页面,具体的复杂逻辑都是交给后端处理, 配合 ajax 异步请求获取调用的数据来实现前端的轻量.
js 引擎则对源代码有了编译的过程, 会将 js 转换成更底层的代码. V8是谷歌德国研究中心编写的, 基于 C++编写的, openSource, 既可以对服务端的 node.js, 也可以对客户端的JavaScript应用.
都知道 V8很快, 可以提升 js 在浏览器中的执行性能, 这是如何实现的呢?
V8 将 js 代码转换成更有效的机器代码而不是作为一个interpreter, 转换时间节点为运行时, 也被成为 JIT(Just-In-Time), 与之对应的还有 AOT(Ahead-Of-Time), 当然这也是很多现代浏览器使用的方法, 比如 Mozilla. 主要的区别在 V8 没有产生字节码以及中间代码.
宏观的看一下引擎的工作?

整个就是一个管道(pipeline)
- 先快速的生成
bytecode字节码, 特点是生成快速但是优化程度不高, 性能不够好; - Profilling data根据函数或对象的热值(hot value)来进行优先收集传到 compiler 中
- 从 Profilling data 到 compile 出机器码(
machine code)会比生成bytecode需要更多的时间, 但是可以极大的提升性能. 如果发现运行到一个地方机器码发生了变化, 那么就会反优化到bytecode, 然后不断重复上述的过程
下面是 V8 的示意图

V8中 interpreter 被叫做Ignition, 优化后的 compiler 被叫做 TurboFan.
以下会解释一些更详细的 V8 特性以及代码优化相关的内容.
Hidden Class 隐藏类
都知道在 JS中没有真正的类, 都是通过原型链来实现, js 也是动态类型的语言, 可以任意的添加或删除类型, 如何有效的访问类型和属性是 V8 的第一个挑战. 他通过在运行时创建一个隐藏类来有一个内部的类型系统以及提高访问属性的时间, 而不是使用一个类字典的数据结构来储存属性然后动态的查找对应的属性(其js引擎就是如此), 来看看这个 hidden class 是什么东西.
function Point(x,y) {
this.x = x;
this.y = y;
}
var p = new Point(11,22);
var q = new Point(33,44);
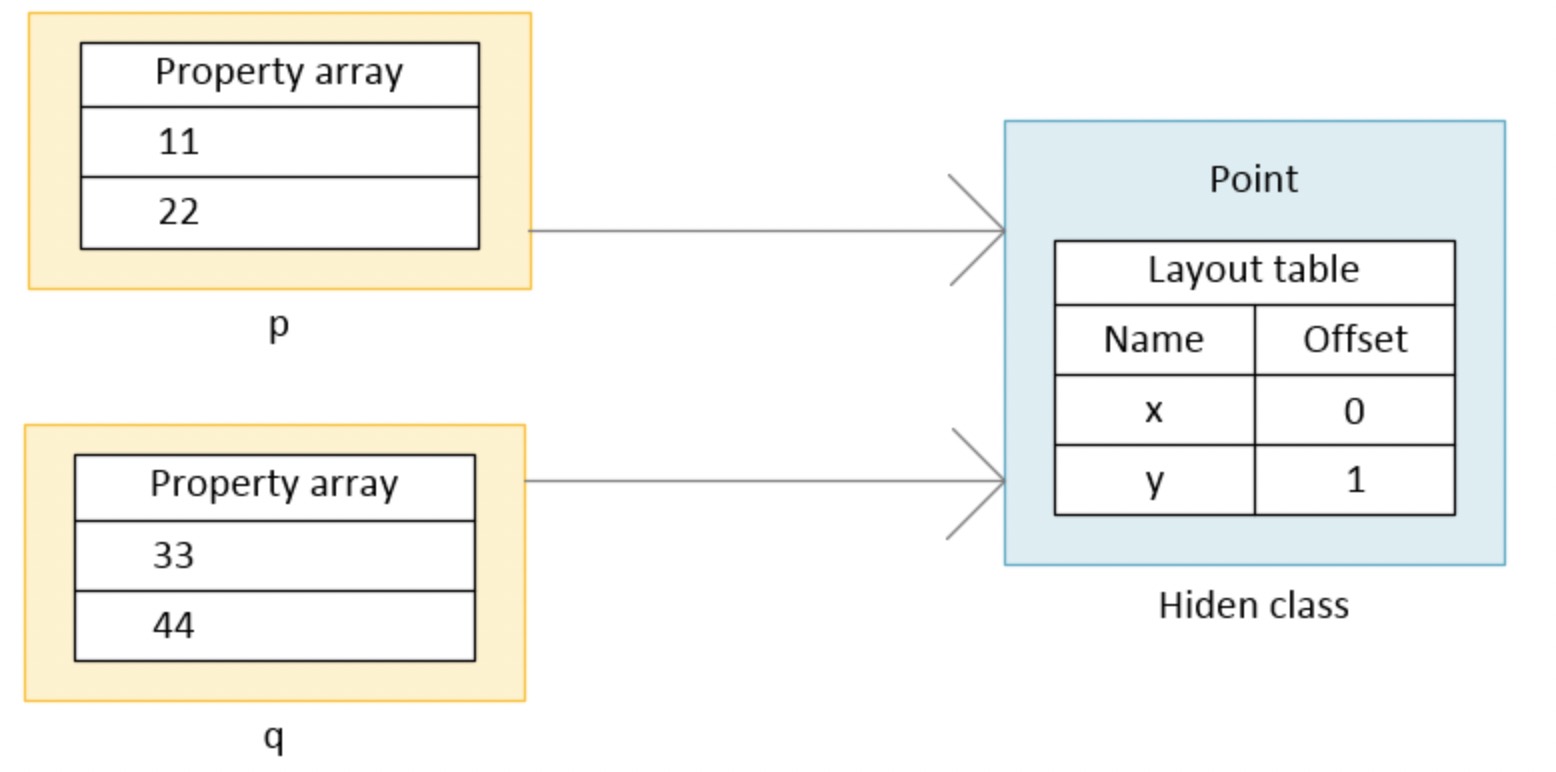
如果两个实例的 layout 是相同的(如上例), p 和 q 就属于 v8 中相同的隐藏类, 他允许 V8 将具有相同属性的对象归类.
现在假设如果向中间添加一个属性 z
function Point(x,y) {
this.x = x;
this.y = y;
}
var p = new Point(11,22);
var q = new Point(33,44);
q.z = 55;
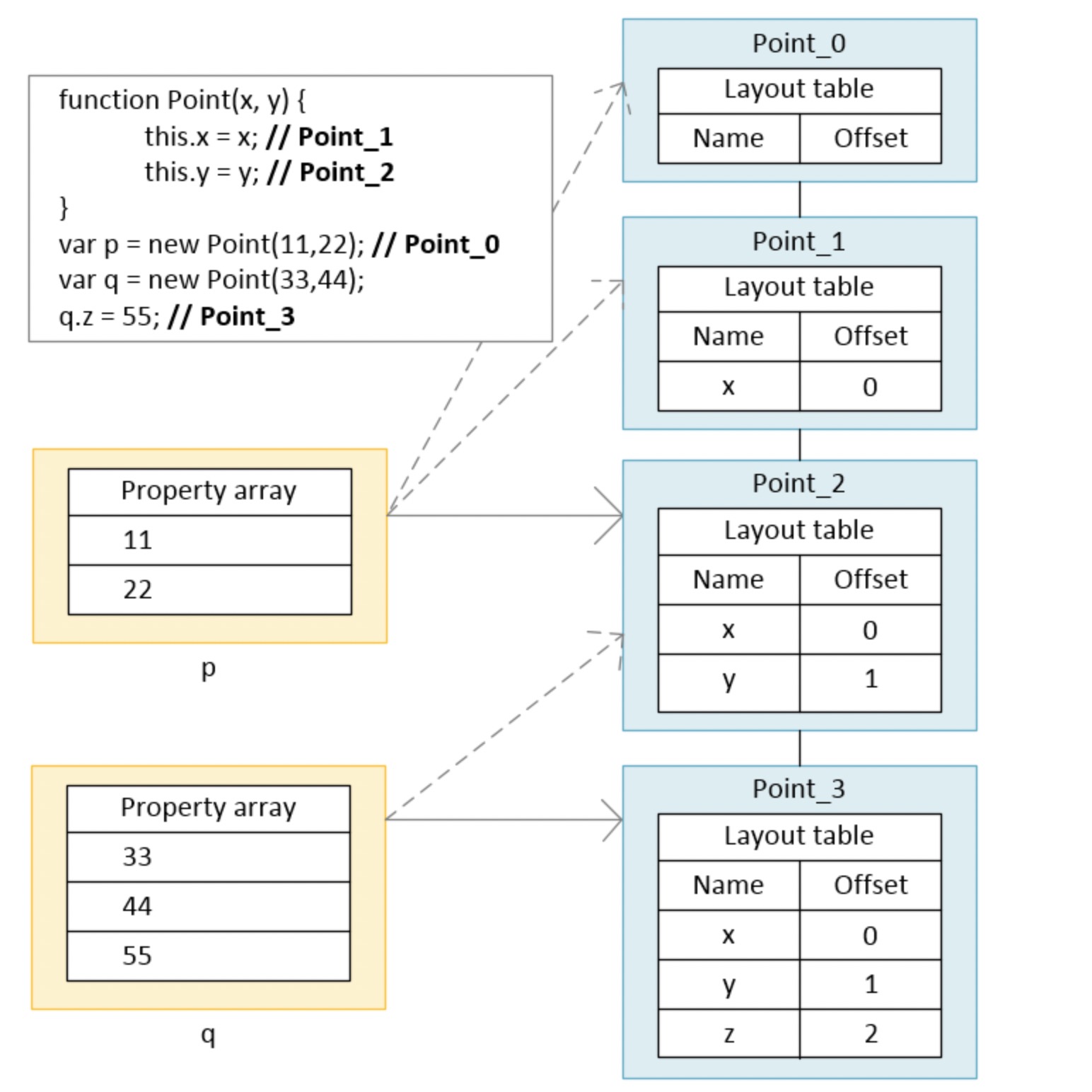
可以看到每次在构造函数中添加新属性的时候都会新建一个 hidden class, 并且保持这些隐藏类更改的 track, 为什么呢? 因为如果两个对象被创建, 并且第二个在创建后新增了新的属性(如上例q 实例增加了 z 属性, 在q 没有新增这个属性之前, 两者是公用同一个隐藏类 Point_2), 那么 V8 需要去追踪到最后一个更改的 hidden class(也就是 Point_2), 并且创建包含新属性的一个新的 hidden class(Point_3)
每次一个新的 hidden class 被创建, 前一个就会通过转换类来表明哪个 hidden class 将会被更新(上例的 Point_0, Point_1)
代码优化
因为 V8 会为每个不同的 layout(layout 的不同包括属性种类的不同, 属性创建顺序的不同)创建一个新的隐藏类, 所以隐藏类的创建应该尽可能的少. 那么就应该避免在创建对象后再添加属性(都在 constructor 中创建), 并且始终以相同的顺序来初始化对象成员(为了避免创建不同的隐藏类树)
class A() {}
var a = new A
a.x = 1
a.y = 2
var b = new A
b.y = 1
b.x = 2
上述代码就会产生 5 个隐藏类. 优化:
class A(){
constructor(x,y) {
this.x = x
this.y = y
}
}
var a = new A(1,2)
var b = new A(2,1)
这样就只会创建 3 个隐藏类.
关于不使用类而使用字面量对象来解释 Transition 链
var o = {}
o.x = 5
o.y = 6
上述 js 代码可以比较方便的解释 shape 的概念, 也就是上文说的隐藏类, shapes 组成的连接关系被称为 Transition 链

可以看到共创建了三个 shape, 甚至都不需要在最新的 shape 中保存所有的属性, 因为可以通过 shape 链进行访问, 也就是

如果创建了两个不同的对象呢? 引擎会尽可能的共享相同的 shape, 如下例中的 empty shape

而如果两个对象没有共享的 shape 呢?例如下例, 那样就是完全独立的两个 Transition 链了.

如果链条较长, 如下例, 一级一级向上搜索十分的缓慢, 时间复杂度为 O(n), 这个时候就需要引入一个 shapetable 来映射这个关系, 把搜索 shape 的复杂度降到 O(1)
const point = {};
point.x = 4;
point.y = 5;
point.z = 6;

但是, 这个 table 会让人很奇怪, 既然这里还要存个字典, 那我当初直接用这个字典不就好了吗?
这时候就要引入 IC(inline cache) 的概念了.IC 会缓存 shape 的调用结果, 在之后的调用中可以快速返回 shape 的 offset 值, 提升对象的查找效率
假设创建了这样一个函数

然后传入{x:’a’}作为参数

因为这是第一次执行,所以使用 get_by_id 去查找对应 shape 的 offset 值, 也就是0

IC会缓存 get_by_id返回的shape 以及 offset, 在之后的调用中遇到相同的 offset 就会立即返回 offset

同构运算: 只在相同的隐藏类上的对象运算. V8 会在调用函数时创建一个隐藏类, 如果我们通过不同的参数类型(是类型而不是参数值)来再次调用, V8 需要创建新的hidden class.所以 使用同构运算而不是使用多态.
更多的 V8 代码优化
值的标记
为了更有效的表示数字和 js 对象, V8 都会使用一个 32bit 的值来表示. 使用一个标记位(1 为对象, 0 为整数, 这个整数被称为 SMall Interger 或者 SMI, 因为只有 31 位了). 如果一个数字大于了 31 位, V8 会封装这个数字, 即转化为 double (双精度) 的值并且创建一个新的对象, 再把这个数字放进去.
代码优化
尽量使用 31 位有符号数字, 来避免昂贵的 js 对象封装运算
Arrays 数组
V8 使用两种不同的方法来处理数组
- 快速元素: 当数组的每个元素都有值的时候, 他们就可以支持一个线性储存buffer来快速访问

- 字典元素: 如果元素中不是每个元素都为普通元素(即不通过 Object.defineProperty 设置属性的元素)或者有空元素, 那么这个数组实际上就是一个 hash 表, 会比快速元素访问更昂贵.

代码优化
保证 V8 都是使用快速元素访问模式, 即避免有空元素, 也不要使用 pre-allocating (预分配大数组), 更好的方式是用多少开多大. 最后, 避免删除数组的元素, 因为这样会将数组为空, 而是使用切片, 创建一个新的数组.
V8 是如何编译 js 代码的?
V8 有两个编译器
-
一个 完整的编译器, 它能对任何 js 生成代码, 好但不是足够好的 JIT 代码. 这个编译器的目标是尽快的生成代码. 他不会对类型进行任何分析, 也就不知道任何关乎类型的东西, 反而它使用 Inline Caches(内联缓存, IC) 策略在程序运行时来增强对类型的获取. IC 是非常高效的, 带来了 20 倍的速率提升, 关于 IC的详细说明点这里
-
另一个是 优化的编译器, 它可以产生足够好的代码对大多数 js 代码.他来得更晚, 并且重新编译了热函数(hot functions), 优化的编译器从 IC 获取类型, 并且决定如何更好的优化代码, 但是一些语言特性不支持的, 比如 try/catch 块. 绕开的办法可以将不稳定的代码放到 function 中, 然后再 try 的 block 中调用该方法.这样, 至少可以将该 function 优化掉.
代码优化
V8 也支持反优化, 因为上述优化的编译器是建立在 IC 可以推测出不同类型的前提下, 反优化则是这些推测是错误的. 比如在最开始说的 hidden class 的产生不是可预期的, V8 将会抛弃优化的编译模式, 回退到完整编译模式去重新从 IC 中获取类型数据. 这个过程是缓慢的并且可以通过尽量少的改变函数来优化掉
代码优化总结
- 尽量使用相同的类, 在构造函数中创建实例属性
- 尽量少的动态添加或删除类的属性, 如果非要的情况下尽可能按照相同的顺序去增加或删除
- 尽可能不适用包含空元素的数组(稀疏数组)
- 标记值尽可能在 31 位以下.
可以去看看这个 slides
引用链接: https://mathiasbynens.be/notes/shapes-ics