History
HTTP 0.9: 单条语句
Tim Berners-Lee 设计了HTTP, 是最初的www的萌芽阶段
- 客户端请求一个单独的ASCII码字符串
- 客户端请求以CRLF结尾
- 服务器响应一个ASCII码流
- 服务端响应一个HTML
- 传输完成后连接终止
比如现在还支持的telnet命令, GET方法进行请求, 没有请求头或其他元数据, 只有HTML, 这是简单得不能再简单的东西.
$> telnet google.com 80
HTTP 0.9的特性:
- 客户端服务端, 请求响应的协议
- ASCII协议, 运行在TCP/IP之上
- 通过HTML进行传输
- 每次请求之后关闭连接
HTTP/1.0 快速增长
91-95年HTML也发展得很快, 出现了一个叫 “网页浏览器” 的软件, 面向消费者的公用网络基础的需求急剧增长
在 Tim Berner-lee的服务器原型之上, 一家名为National Center of Supercomputing Application(NCSA)的团队做出了第一个受欢迎的浏览器 NCSA Mosaic, 在1994年成立了Mosaic Communication 公司, 最后被更名为网景(Netscape), 在1994年12月发展出了网景导航1.0版本
HTTP/1.0的请求长这样:
$> telnet website.org 80
Connected to xxx.xxx.xxx.xxx
GET /rfc/rfc1945.txt HTTP/1.0 --*1
User-Agent: CERN-LineMode/2.15 libwww/2.17b3
Accept: */*
HTTP/1.0 200 OK --*2
Content-Type: text/plain
Content-Length: 137582
Expires: Thu, 01 Dec 1997 16:00:00 GMT
Last-Modified: Wed, 1 May 1996 12:45:26 GMT
Server: Apache 0.84
(plain-text response)
(connection closed)
*1 HTTP版本的请求行, 紧跟着是请求头
*2 相应状态, 紧跟着响应头
跟HTTP 0.9相比有如下改变:
- 请求可以有多个独立头字段的新行组成
- 响应对象会有一个相应状态行
- 响应对象有自己的一套独立头字段的新行
- 不仅仅限于hypertext超文本
- 连接在每个请求之后关闭
每个请求都需要一个新的TCP连接导致了性能上的瓶颈, 三次握手的慢启动
HTTP/1.1 互联网标准
第一个HTTP/1.1标准在1997年发布, 大概就在1.0版本后的6个月时间. 两个半年后, 1999年, 1.1的一些改进和升级被发布
HTTP/1.1 有如下优化
- keepalive
- chuanked encoding transfers
- byte-range 请求
- 更多的caching机制
- 传输编码
- 请求管道化
$> telnet website.org 80
Connected to xxx.xxx.xxx.xxx
GET /index.html HTTP/1.1 ---*1
Host: website.org
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_4)... (snip)
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Encoding: gzip,deflate,sdch
Accept-Language: en-US,en;q=0.8
Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.3
Cookie: __qca=P0-800083390... (snip)
HTTP/1.1 200 OK ---*2
Server: nginx/1.0.11
Connection: keep-alive
Content-Type: text/html; charset=utf-8
Via: HTTP/1.1 GWA
Date: Wed, 25 Jul 2012 20:23:35 GMT
Expires: Wed, 25 Jul 2012 20:23:35 GMT
Cache-Control: max-age=0, no-cache
Transfer-Encoding: chunked
100 ---*3
<!doctype html>
(snip)
100
(snip)
0 ---*4
GET /favicon.ico HTTP/1.1 ---*5
Host: www.website.org
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_4)... (snip)
Accept: */*
Referer: http://website.org/
Connection: close ---*6
Accept-Encoding: gzip,deflate,sdch
Accept-Language: en-US,en;q=0.8
Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.3
Cookie: __qca=P0-800083390... (snip)
HTTP/1.1 200 OK ---*7
Server: nginx/1.0.11
Content-Type: image/x-icon
Content-Length: 3638
Connection: close
Last-Modified: Thu, 19 Jul 2012 17:51:44 GMT
Cache-Control: max-age=315360000
Accept-Ranges: bytes
Via: HTTP/1.1 GWA
Date: Sat, 21 Jul 2012 21:35:22 GMT
Expires: Thu, 31 Dec 2037 23:55:55 GMT
Etag: W/PSA-GAu26oXbDi
(icon data)
(connection closed)
*1 请求HTML文件, 需要编码格式, 字符集, cookie元数据
*2 原始HTML请求的块(chunked)响应
*3 以ASCII十六进制表示chunk的字节数(256位)
*4 chunk流的结束响应
*5 在同一个TCP连接中请求icon
*6 通知服务器连接不会再被重用
*7 icon响应, 接着关闭连接
HTTP/1.1中的keepalive为默认开启, 如果不想使用需
Connection: close的请求头, 在HTTP/1.0中需要使用Connection: Keep-Alive
HTTP/2: 改善传输性能
随着业务的增长, 用户和web开发真越来越需要接近实时的响应传输和更高协议性能要求, 在HTTP/1.1上修修补补已经不能满足要求了, 所以在2012年有了HTTP/2, HTTP/2有更低的延迟和更高的吞吐量, 但是并没有改变高级协议的语法: 所有的请求头, 值, 使用场景都一样.
任何已有的应用都可以不做任何改变的在HTTP/2中传输. 只是服务器会通过HTTP/2进行响应.
虽然最终的HTTP/2协议标准已经完成, 但是依然需要在可预期的未来兼容HTTP/1.1, 大概还要10年左右吧.
网络性能优化要点
在前两篇博客中已经谈到了物理层和协议的优化, 包括
- 延迟和带宽对网络性能的影响
- 传输协议(TCP, UDP)对HTTP的限制
- HTTP协议本身的特性和缺点
- 网页应用的趋势和性能需求
- 浏览器限制和优化
超文本, 网页和网页应用
- 超文本
- www(world wide web)的起源
- 包含一些基本格式和支持超链接的纯文本
- 网页
- HTML是作为早期的浏览器版本中超文本的扩展, 可以支持更多的媒体资源, 比如图片和audio, 并添加了很多其他的丰富的布局
- 十分的好看, 但是没有多少交互, 跟一张打印的纸差不多
- 网页应用
- 加上了JS和DHTML(dynamic)和Ajax的可交互的网页.
- 使用复杂图形化脚本, stylesheet和标记的新时代
HTTP0.9会话包含单个文档请求, 足够传输超文本(单document, 一个TCP连接,然后便关闭), 优化的空间仅仅在于短live TCP连接的单个HTTP请求. 然后网页的到来使得单document到document + 依赖的资源, HTTP/1.0引入了HTTP 元数据概念(header), HTTP/1.1面向性能优化为首要任务改进了它, 比如定义了caching, keepalive等. 所以多TCP连接可以实现, 性能的关键从document load time 到 page load time(PLT: 浏览器不再转圈的时间, 技术上说就是onload时间触发的时候, 这个时候js, image等依赖的资源都已经加载完毕) 网页应用使用媒体改进了普通网页, markup 定义基本结构, stylesheet定义layout, 脚本构建交互应用的结果并响应用户输入,而且可能会同时修改stylesheet和markup 结论是page load time 逐渐在性能上跟不上了, 因为都是动态的交互网页应用, 而不是静态的网页, 如何衡量加载每一个资源的时间, 现在需要回答下列几个具体的问题:
- 什么是加载过程的里程碑?
- 用户什么时候可以第一次交互
- 什么用户的交互应该被引入
- 每个用户参与交互和转化率是多少
DOM, CSSOM, 和JS
DOM解析HTML文档, 同时CSSOM(CSS Object Model)构建具体的样式表和资源, 两者共同生成 渲染树, 这是浏览器可以呈现布局信息以及显示在屏幕上的时刻 但是还有JS, 可以通过同步的写操作(doc.write)阻塞DOM解析, 并且也可以查询任何对象的样式, 所以DOM被js阻塞, js被CSSOM阻塞 这是为什么css在头, js在尾的最佳时间的原理, js会阻塞css, 渲染和脚本的执行都会被css阻塞.
剖析现代网页应用
通常的网页(2013年的数据):
- 90个请求, 从15个host获取数据, 1311KB被传输
- HTML: 10个请求, 52KB
- Image: 55请求, 812KB
- Javascript: 15请求, 216KB
- CSS: 5请求, 36KB
- 其他 5请求, 195KB
现在可能翻番都不止了.
不像桌面应用, web应用不需要安装, 输入URL, 点击Enter, 就可以运行, 但是桌面应用只需要付出一次安装成本, 但是网页应用需要每次访问都进行一次”安装”–资源下载, DOM和CSSOM的构建, JS的执行.
速度, 性能和人的接收程度
速度和性能是相对的概念, 每个应用基于商业标准, 应用场景, 用户期望, 任务的复杂度等因素有自己的一套需求.下表是用户的感知与延迟长短的关系
| Delay | User perception |
|---|---|
| 0–100 ms | Instant |
| 100–300 ms | Small perceptible delay |
| 300–1000 ms | Machine is working |
| 1,000+ ms | Likely mental context switch |
| 10,000+ ms | Task is abandoned |
250ms内渲染出页面, 或者只好提供视觉反馈是让人觉得好的网页性能的非官方标准
但是DNS查找, 接下来的TCP握手, TLS的建立, 典型网页请求的几个来回, 很容易就超过100-1000的预算, 所以移动或者说无线网络对快速网页性能有极大的需求.
性能越快, PV越高, 钞票越多.
分析数据瀑布
数据瀑布是诊断网络性能的工具, 每个浏览器都提供了查看的方法, 也有一些在线的工具, 比如WebPageTest(此工具需翻墙).

yahoo主页消耗了683ms去下载, 超过200ms都是等待网络, 也就是30%, 然后请求了一大堆的资源, 看下图, 一共52个, 超过30个不同的逐渐, 添加了486KB
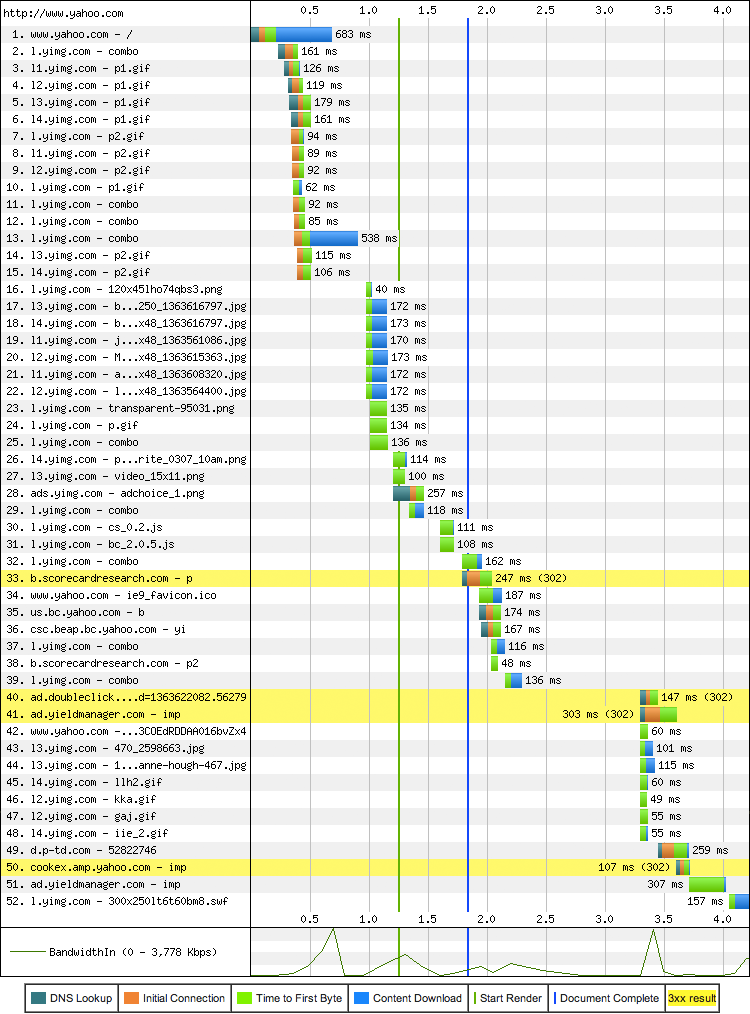
要注意,在获取www.yahoo.com的document的时候, 新的HTTP请求也被发出 HTML解析是渐进式的, 允许浏览器尽早的发现需要的资源, 并且并行的发出必要的请求.注意绿色的那根线, 表示 “start render”, 这时候所有的资源还没有完全加载, 允许页面边加载, 用户也可以进行交互. 实际上, “Document Complete”事件在蓝色的那根线时触发, 也在剩余资源被加载前.换句话说, 浏览器已经不转圈了, 用户可以继续任务, 但是仍然逐渐的在后台增加新的内容. 比如广告和社交部件.
性能优化不仅仅是前端, 仔细看上图可以看蓝色部分为下载的数据, 绿色部分为TCP握手部分和DNS查找以及等待接收响应的第一个数据的其他网络延迟, 显然蓝色占的比例并不算大, 所以如何减少绿色的部分是后端需要考虑的部分.
最后检查带宽利用率, 可以看到是突发的短时的, 利用率非常的低.这也可以看出带宽不再是大多数网页应用的限制因素, 而是之前一直所说的往返于客户端和服务器之间的延迟
性能来源: 计算, 渲染和网络
网页程序主要包括三个任务
- 获取数据
- 页面布局和渲染
- JS执行
渲染和脚本是单线程的, 交叉执行的model, 不能并发修改正在生成的DOM. 就算优化了JS的执行和渲染, 如果浏览器因网络阻塞也会前功尽弃, 所以迅速获取到网络资源是第一优先级.
更多的带宽并不那么重要
带宽重要, 但是没那么重要, 毕竟每一个ISP和移动运营商一直提醒着高带宽的好处: 更快的上传和下载. 接入更高的带宽固然是好事, 特别时在大量数据传输的时候, 比如video和audio streaming, 但是发生在每天的网页浏览上, 我们是需要成百上千相对小的资源, 向数十个主机请求, 来回的延迟才是限制因素
- yahoo网站中的HD 视频流的限制因素是带宽
- 加载yahoo主页的限制因素是延迟
那为什么处理那么大流量的视频和音频流时都hold得住(现在各种小视频风靡中国), 但是小而短的连接却成了难题呢?
延迟时性能的瓶颈
已经在之前的章节说了很多次为什么延迟时当今每个网页浏览器的限制因素.

带宽在4Mbps之后基本上加载事件就保持不变了, 但是延迟是一直减少的
移动网络的延迟比有线更高, 所以对移动网络的延迟优化更加至关重要.
人造和真实用户性能衡量
如果可衡量, 那么就可以优化.
通常来说人造数据是在一定的可控制的测量环境下生成的. 每个测试可对应不同的部分, 比如应用服务器吞吐量, 数据库性能, DNS时间等, 然后提供一个基准线帮助检测系统的某个组件性能.
但是人造数据是不足够定位所有的性能瓶颈, 特别是有很多外在条件共同作用决定用户最终体验的场景下.
- 场景和页面选择: 完全复制用户的导航模式是很难的
- 浏览器缓存: 性能很大成都上会基于用户缓存状态
- 中间件: 性能会因为基于中间代理或缓存而大有不同
- 硬件区别: CPU, GPU, 内存性能
- 浏览器区别: 不同种类的浏览器, 相同浏览器的不同版本
- 可连接性: 真实连接中不断改变的带宽和延迟
W3C制定了一个数据聚合处理的Navigation Timming API

这些API暴露了以前无法获取到的数据, 比如通过标准化的 performance.timing(可在任意浏览器中打印该数据) 对象获取DNS和TCP连接次数(更高精度, 精确到毫秒). 通过获取该数据, 可以观察真实世界的应用性能.
function init() {
// 储存相关任务的时间戳
performance.mark("startTask1");
// 执行应用代码
applicationCode1();
performance.mark("endTask1");
logPerformance();
}
function logPerformance() {
var perfEntries = performance.getEntriesByType("mark");
// 循环打印用户timing数据
for (var i = 0; i < perfEntries.length; i++) {
console.log("Name: " + perfEntries[i].name +
" Entry Type: " + perfEntries[i].entryType +
" Start Time: " + perfEntries[i].startTime +
" Duration: " + perfEntries[i].duration + "\n");
}
// 打印Navigation Timing 对象
console.log(performance.timing);
}
浏览器优化
浏览器的远远不止一个网络套接字那么简单, 浏览器变得越来越智能:提前解析DNS查找, 提前连接可能的终点, 提前获取并且按资源的优先级排序等. 以下两类是核心优化点
- Document-aware optimization 文档感知优化
- 熟悉网络协议, 了解document, css和JavaScript解析管道
- 尽早关键资源,使页面尽早可以达到交互状态
- 都是通过资源优先级分配, 提前解析或者类似的技术
- 推测行优化
- 学习用户导航模式, 推测用户可能的动作
- 提前解析DNS, 提前连接可能的主机名
有四种技术被应用在主流的浏览器上
- 资源提前获取并并排列优先级
- DNS 提前解析
- TCP提前连接
- 页面提前渲染
具体可参见 谷歌浏览器的优化
如何利用好这些browser的优化特性?
- 关键资源比如css和js应尽早出现在文档中
- css应该尽早被传输, 因为会阻塞js执行
- 非关键js应该被延后, 以免阻塞DOM和CSSOM
- HTML文档是逐渐被解析的, 所有文档应该间歇发送以获得最佳性能
<!-- 提前解析hostname -->
<link rel="dns-prefetch" href="//hostname_to_resolve.com">
<!-- 提前获取关键资源 -->
<link rel="subresource" href="/javascript/myapp.js">
<!-- 提前获取现在或将来导航的资源 -->
<link rel="prefetch" href="/images/big.jpeg">
<!-- 提前渲染具体的页面在用户的下一个目的地 -->
<link rel="prerender" href="//example.org/next_page.html">
对大多数用户甚至网页开发者来说, DNS, TCP和SSL延迟是完全透明的, 都是在网络层被协商的, 但是每一步都关乎用户体验, 通过帮助浏览器预期这些往返延时, 能够移除掉这些瓶颈, 是传输更快.
HTTP/1.x
对HTTP/1.0来说优化很简单, 全部的部署升级到HTTP/1.1
- 持久连接, 可重用性
- 响应流的块传输编码
- 请求管道允许并发请求处理
- 字节服务以支持range的资源请求
- 提升了缓存机制
HTTP/1.1的优化甚至可以单独出一本书, 因为覆盖的范围实在太广了.看几条其他书籍中关于网络优化的建议
- 减少DNS查找
- 更少的HTTP请求
- 使用内容传输网络(Content Delivery Network: CDN)
- 添加过期头和ETag的配置
- GZip
- 避免HTTP重定向
持久连接的好处
假设发送两个小文件资源(<4KB的css和HTML每一个会消耗服务器任意的时间(20ms到40ms),

不能预测服务器处理时间, 根据资源和后端能力的不同, 但是需要强调通过TCP连接最少请求传输时间为2个来回, 一个是握手, 另一个是请求响应.这是之前非持久性HTTP会话的固定消耗.
持久连接边少了除第一次的”三次握手”以外的”三次握手” 也避免了TCP在第一次之后的慢启动.

两个请求节约了1个RTT, 如果是N个请求, 那么就减少了(N-1)*RTT. 默认的HTTP/1.1请求头里Connection: Keep-Alive.
HTTP管道
持久的HTTP允许在多个请求中重用已有的连接, 但是遵循FIFO的队列顺序.只有在前一个请求获得相应之后才会发出下一个请求.HTTP管道是一个很小但是很重要的工作流优化, 可以重排列这个FIFO队列. 尽早把请求发出, 服务器可以在处理完第一个请求之后立即继续下一个请求, 甚至如果服务器支持多线程, 还可以并发同时处理两个请求, 这样就可以省去除了第一次之外的其他请求延时

使用上述两种机制,就把延迟从284(152+132)ms降低到了172ms(-40%), 仅仅使用了一个如此简单的机制.
如果服务器可以并发处理

但是HTTP/1.x协议严格返回响应的序列化.就是不允许多个响应在同一个请求复用.强制每个响应必须完全返回后才能响应下一个请求.
- HTML和CSS虽然同时到达, 但是HTML先请求
- 服务器开始并发处理, HTML消耗40ms, CSS消耗20ms
- CSS请求完成但指能存在buffer中等待HTML响应被发送
- 一旦HTML响应被发送, CSS也被从buffer中取出发送
尽管CSS先处理完但无法发送, 需等待HTML的这个过程成为 线头阻塞head-of-line blocking
- 降低了网络连接的利用率
- 服务器缓存的花销
- 不可预计的延迟时间, 比如如果第一个请求一直挂起,或者仅仅就是需要服务器处理很长时间, HTTP/1.1就是必须阻塞的等着
尽管pipeline有众多的优势, 但是包含上述的线头阻塞, 以及下列缺陷:
- pipeline这个特性还不被许多中间件支持, 使用pipeline可能会中断传输
- 一次失败的响应还需要重发(TCP的丢包重发特性)
基于以上的问题, pipeline使用场景非常有限.浏览器只将其作为高级配置选项, 通常是默认关闭.
使用多TCP连接
现在主流的浏览器, 包括桌面和移动端, 对单个主机开放最多6个连接.
- 客户端可以并行的发6个请求
- 服务端可以并行处理6个请求
- 在第一次往返的累计包的数量(TCP cwnd)提升为原来的6倍
多连接的花销
- 额外的socket资源消耗(收发两端和所有的中间件): 包括额外的内存和cpu负载, 这是最重要的消耗
- 并发TCP流的带宽竞争
- 为了处理一整坨sockets需要更高的集成度, 开发成本高
- 应用的并行能力限制
之所以使用的原因:
- 绕过HTTP协议限制的权宜之计
- 绕过TCP起始拥塞窗口体积小的权宜之计
- 为不能使用TCP窗口缩放的客户端提供权宜之计(参考之前提到的带宽延迟积(BDP))
只要升级到最新的OS kernal, 那么cwnd都被提升到了10个packets, 也都支持窗口缩放, 但是依然没有方法可以绕开HTTP/1.x多路复用的问题.
浏览器限制每个主机允许的最大连接数可以白虎无意(或有意的)DoS(denial of service)攻击. 如果没有这个限制, 客户端可以透支服务器所有的资源. 可是客户端如果已经发出6个并发的请求, 在发第七个的时候会一直阻塞的等待前6个的响应回来. 对于实时交付数据的应用而言, 客户端的连接数限制会产生问题, 比如websocket, ServerSentEvent, 和挂起XHR, 这些会话都会占用一整个TCP, 不管有无数据, 所有一定小心不要自己对自己实施DoS攻击
域名分片(Domain Sharding)
之前说过了浏览器最多会创建6个TCP连接, 好消息时所有的连接管理都是浏览器自己完成, 但是有时候6个连接可能也不够用, 但是这里有个可以绕开的点, 对同一个origin时6个, 但并不是同一个IP, 想多个域名进行请求, 但是这几个域名都是指向同一个IP, 那么就可以有多于6个的连接, 域名越多, 并发越多
当然也有问题:
- 需要更多的DNS查找
- 不能复用TCP长连接了
- 每个新域名必须经历一次TCP的三次握手和慢启动
- 在小资源的请求上得不偿失. 具体应该分多少个域并没有一个明确的规定, 取决于网页的资源和客户端可用的带宽和延迟.
不要过度使用分片, 这样会导致TCPstream利用率下降, 特别是HTTPS使用之后还有TLS的握手, 时间会更长
测量和控制协议负载
HTTP0.9十分的简单, 就一行ASCII请求, HTTP/1.0扩展了可以添加请求和响应头, 来交换收发的元信息, 最后HTTP/1.1使这个标准化, 头hi非常容易被浏览器和客户端修改和扩展的, 并且一直以纯文本的形式发送以向前兼容
现在, 许多浏览器会在请求中携带额外的500-800字节的元信息
- 用户代理
- accept的header
- transfer的header 以上两点都几乎不会改变
- 缓存指令
但500-800是还没有计算HTTP cookie的情况, 这些所有加在一起放在未压缩的HTTP元数据里, 会增加几个KB那么多的额外开销
没有对HTTP/1.1的的HTTP头限制大小, 但是许多服务器和代理会限制在8KB到16KB里
你可以看到只为传输{“msg”: “hello”}这15字节的数据, 一共花了218字节的请求头
$> curl --trace-ascii - -d'{"msg":"hello"}' http://www.igvita.com/api
== Info: Connected to www.igvita.com
=> Send header, 218 bytes
POST /api HTTP/1.1
User-Agent: curl/7.24.0 (x86_64-apple-darwin12.0) libcurl/7.24.0 ...
Host: www.igvita.com
Accept: */*
Content-Length: 15
Content-Type: application/x-www-form-urlencoded
=> Send data, 15 bytes (0xf)
{"msg":"hello"}
<= Recv header, 134 bytes
HTTP/1.1 204 No Content
Server: nginx/1.0.11
Via: HTTP/1.1 GWA
Date: Thu, 20 Sep 2012 05:41:30 GMT
Cache-Control: max-age=0, no-cache
拼接和组合
- 拼接
- 许多JS和CSS文件被拼接在单个文件中
- Spriting 组合
- 许多图片被组合成一张大的图片(雪碧图)
好处:
- 减小协议开销
- 因为是单个资源, 节省了对每个文件进行请求的协议开销
- 在应用层应用管道
- 实际上很像应用层的管道(pipeline), 因为也是复用的多个资源, 将多个资源合并在了一起. 缺点:
- 相同类型的所有资源必须在同一个URL下(缓存键)
- 合并的bundle很可能包含当前页面不需要的资源
- 单次升级任意一个文件都会导致整个大文件的更新.需要客户端重新下载缓存
- JS和CSS都是只在传输完成之后进行解析和执行, 体积增大会减缓应用的速度
- image的缓存会占据内存大小. 因为会一直使用image, 所以不会被释放, 8006004 = 1920000bytes = 1.83MB
但是现在很多都是单页应用(SPA), 这些缺点的部分可以被掩盖.但也有优化的空间, 比如利用HTML的渐进式渲染, 可以分批请求之后render的资源.尽快render
看看Gmail的优化:
- 把首次绘制所需的CSS单独拿出来, 优于其他css传输
- 递增地传输js实现递增执行
- 自定义外部更新机制, 客户端自动在后台更新js, 在页面下次刷新时应用.
嵌入资源(行内资源)
可以传输图片, PDF甚至音频, URI的格式为(data:[mediatype][;base64],data)
<img src="data:image/gif;base64,R0lGODlhAQABAIAAAAA
AAAAAACH5BAAAAAAALAAAAAABAAEAAAICTAEAOw=="
alt="1x1 transparent (GIF) pixel" />
IE8有对URI的大小限制, 最大为32KB 行内资源对小的唯一的资源时非常好用的, 行内的资源不会被缓存, 所以如果需要多个地方使用该资源, 应放弃行内的方式. 而且base64这种文字编码方式会增大33%的体积.所以只使用域小型的文件, 大概多小呢? 1-2KB吧.
如果有很多小的单独的文件, 需要考虑下述原则:
- 文件小, 限制在某个页面, 不复用, 考虑行能
- 文件小但是在不同页面会重用, 考虑bundle
- 小文件经常更新, 单独维护
- 降低HTTP cookie来最小化协议负载
HTTP/2
HTTP/2的目标:
- 通过开启完整请求和响应的多路复用减少延迟
- 通过高效压缩HTTP头字段最小化协议开销
- 添加请求优先级排序功能
- 服务器推送
HTTP/2没有修改任何HTTP的核心概念, 比如HTTP方法, 状态码 URI, 头字段, 只是
- 修改了这些数据的格式
- 在传输过程中, 收发双端都可以对整个过程进行控制
- 通过新的framing层对应用隐藏所有的复杂性
- 现有的应用可以在不做任何修改的情况下进行传输
为什么不是HTTP/1.2 因为HTTP/2中引入了新的二进制framing层, 不能向下兼容HTTP/1.x的服务器和客户端.
SPDY和HTTP/2的历史
SPDY谷歌2009年研发的实验性协议, 目标是:
- 减少50%的页面加载时间(plt)
- 不修改现有网路的代码
- 最小化部署复杂度, 不改变网络层级架构
- 开源开发此新协议
- 通过实验性协议获取真实的性能数据.
为了完成50%的PLT目标, SPDY通过引入新的二进制framing层, 高效的利用了TCP层, 可以允许收发双端进行多路复用, 优先级排序, 头字段压缩.已经是HTTP/2的雏形了.
HTTP Working Group学习并改进了SPDY, 推出HTTP/2标准. HTTP/2只是extending, 没有replacing 之前的HTTP标准.那意味着高层级的API是保持不变的, 但是理解低层级的原理十分重要
二进制分帧层

这个层为应用提供了一个新的优化编码机制, 在socket接口和更高的HTTP API之间.
- HTTP 语义没有影响, 但是传输时的编码是不同的
- verbs
- methods
- headers
- HTTP/1.x是纯文本协议 HTTP/2是分成了好几个小的消息和帧, 每个都是二进制编码格式
- 收发双端都需要去理解这个二进制编码机制, HTTP/1.x客户端就无法理解HTTP/2 only的服务器, 反过来也一样
- 客户端和服务端自己会进行必要的分帧而无需手动设置
优点
- performant, robust, provably correct implementation
缺点
- 需要工具去解析并调试
- Wireshark
- 本来需要同样的工具去inspect加密的TLS流, 他是依靠二进制分帧携带HTTP/1.x或HTTP/2的数据来实现的
流, 消息和帧
- 流 stream
- 在已建立的链接中的双向流动的字节, 可以携带一个多多个消息
- 消息 message
- 一个完整的帧序列, 映射请求或响应的消息
- 帧 frame
- 最小的HTTP/2通信单位
- 每个都包含帧头, 也就是为每个帧归属的最小的流定义
- 所有通信是通过单TCP连接, 携带了许多双向流
- 携带双向消息的每个流有独立的标识和可选的优先级信息
- 包含一个或多个帧的每个消息是一个逻辑上的HTTP消息, 比如请求或响应
- 帧是最小的通信单位, 可以携带具体类型的数据,比如
- HTTP 头
- 消息payload
- 不同流之间的帧可能是交叉的, 然后通过在每个帧头里面嵌入的流标识进行重新组装

HTTP/2把HTTP协议打散成二进制编码的交换帧, 帧上有具体的流属性信息, 所有的都可以在单个TCP连接里面多路复用. 这是HTTP/2协议的其他特性和性能优化的基础
请求和响应多路复用

打散成独立的帧, 交叉传输, 然后在另一边进行重组, 上图就表示同时有3个流在传递, 这个特性影响巨大:
- 平行的交叉多个请求或响应不会阻塞任意一个
- 使用单个连接平行的传输多个响应或请求
- 移除不必要的HTTP/1.x的临时方案, 比如拼接文件, 雪碧图, 分域名
- 去掉了不必要的延迟并提高了网络容量的利用率, 获得了更低的PLT
流的优先级
因为HTTP消息会被分成许多单个的帧在多个流里进行多路复用的传输, 所以权重和依赖需要有一个标准
- 每个流可以被赋予1到256的整数权重值
- 每个流可以被赋予一个显示的对其他流的依赖
依赖和权重的组合可以允许客户端构建并且传输 “优先级树”(见下图), 服务器会根据优先级的信息控制分配的CPU, 内存和其他资源, 一旦响应数据准备好了, 就分配带宽来保证最优的高优先级响应传输.

流的依赖声明式通过引用一个其他流的唯一标识作为父级, 如果没有的这个声明, 这个流便是独立的”根流”.声明流表示如果可能的化, 父流应该先被分配资源, 也就是上图中的, 请先传输D在传输C的响应.
如果像AB那样兄弟间传输的话, 分配资源的权重应该是两者和, 每个流占比不同
- 权重和
4+12 = 16 - 将每个流的权重占比:
A=12/16 B=4/16
上图从左往右的解释:
- A和B都没有说明父依赖, 也就是都是根流, B占1/3A的资源
- D是根流, C依赖D, D应该在C之前分配所有的资源, C权重高(8>1)但”依赖优先”
- D在C之前分配所有的资源, C应该在AB之前分配所有资源, B获取A1/3的资源
- D在E和C之前获取所有资源,E和C在A,B前获取相同的分配, B获取A1/3资源
浏览器请求优先级和HTTP/2 HTML 文档是构建DOM不可或缺 –> 构建CSSOM需要CSS –> DOM和CSSOM的构建都会被JavaScript阻塞 –> 其他剩余资源(图片, 通常低优先级) 为加快PLT, 浏览器会基于资源的类型, 在网页中的位置, 甚至根据之前访问来学习优先级, 比如如果渲染在之前某个访问中被某个资源block了, 相同的资源就会在以后变高 排队请求和线头阻塞都被HTTP/2解决了, 浏览器可以在请求被发现时将所有请求一起发出, 浏览器可以通过权重和依赖标记stream的优先级, 可以让服务器在响应里优化传输
每个origin 只有一个连接
因为有了二进制分帧, 所以不再需要多个 TCP 连接平行复用, 每个流被分成了许多帧, 每个帧可以交叉和排序. 到最后, 所有的 HTTP/2 连接都是持久化的, 而且每个 origin 只有一个连接, 由此提供了许多性能优势
许多的 HTTP 传输是短的并突发的, TCP 被优化成长连接且大量数据的传输. 通过重用 HTTP/2中相同的连接可以更高效利用 TCP 连接, 也降低了整个协议的负载.更少的连接对不管是客户端还是中间件还是服务端都减小了内存, cpu 的消耗, 对吞吐量的提升和减小运行成本都有帮助
丢包 高 RTT 连接, HTTP/2的性能
之前都是 HTTP/2的优点, 难道就没有什么缺点吗?
- 终止了 HTTP 层面的线头阻塞, 但是依然存在 TCP 层面的线头阻塞
- 如果 TCP 串口缩放被禁止的话, 带宽延迟积的影响可能会限制连接吞吐量
- 当丢包发生时, TCP 拥塞窗口的大小会减小, 同时也会影响整个连接的最大吞吐量
但是这些相比于多请求发送利大于弊, 因为复用同一个请求的好处实在太大. 而且在 TCP 层面也可以解决一部分问题比如 TCP Fast Open, 丢包时按比例减小(Proportional Rate Reduction), 增加初始拥塞窗口等.也要记住, 就算是没有不用TCP和UDP用其他协议也可以跑在HTTP/2的协议上
flow控制
flow控制机制是防止发端发送过多的数据到收端, 导致收端处理不过来, 比如
- busy
- 正在 heavy load
- 为特定流分配固定的资源
HTTP/2提供了一套简单的机制可以让收发双端部署他们自己的流和连接级的 flow 控制
- flow 控制是方向性的, 每个收端可以选择任意窗口大小, 可以定义单个流和整个连接
- flow 控制是基于可信任的, 每个收端公布初始连接和流控制串口( bytes ), 当发端发送一个DATA帧会被减小, 当收端发送WINDOW_UPDATE帧会被增加
- flow 控制不能被禁止, 当 HTTP/2连接建立后, 收发双端会交换SETTINGS帧, 这回同时设置两个方向的流控制窗口. 默认流控制窗口设置为65535bytes, 但是收端可以设置最大的窗口值(2^31 - 1)bytes, 并且通过接收到任何数据时发送 WINDOW_UPDATE帧来维护
- 流控制是跳对跳的, 而不是段对端, 意味着可以使用中间件去控制使用的资源, 并且基于自由的标准部署资源分配机制.
这个跟TCP的流量控制本质上是一样的, 但是TCP的流量控制不能对同一个HTTP/2复用的流进行区分, 所以就需要它了.
举例: 应用层流控制允许服务器只获取一部分特定资源, 通过降低流控制窗口到0来暂停获取, 并且也可以在之后继续, 比如先获取一张图片的预览图, 先展示, 然后允许更高优先级的获取, 并且在完成加载之后继续获取更多的关键资源,
服务器推送
服务端在收到某个客户端的请求后, 不仅会发送该请求对应的响应, 也会将未来客户端可能需要的资源一并发送.下图就是客户端发送请求index.html. 服务器将js和css都发送过来了, 避免再次发请求.

其实之前使用的行内资源就已经算是使用了服务器推送了.HTTP/2实现了同样的效果, 而且还有额外的好处
- 可以被浏览器缓存(行内资源不会)
- 可以在不同页面中共享
- 能与其他资源多路复用
- 被服务器排优先级
- 可被客户端拒绝 唯一的安全限制是浏览器强制推送资源必须遵从同源策略, 即服务器必须为提供内容授权
PUSH_PROMISE 101是服务器在需要预推送时发回给客户端, 让客户端知道之后就不用请求这些数据了和客户端可以通过发RES_STREAM帧进行拒绝(因为有可能资源已经缓存下来了, 不用额外请求), 这个拒绝的特性跟推送的功能一样重要. 客户端可以用之前说的流量控制来控制接收的预推送熟练限制, 甚至完全拒绝接收预推送
头部压缩
头部表示请求的元数据, 在HTTP/1.x中大概有500-800比特, 如果加上cookie的话就会到千字节. HTTP/2使用 HPACK 压缩, 包含下列两个技术:
- 允许传输静态 Huffman 编码的头
- 需要客户端和服务端维护并更新一个索引列表, 包含之前的请求头字段

更多的优化: HPACK压缩包含了静态和动态的表
- 静态定义标准, 提供一个通用HTTP请求头字段
- 动态初始化为空, 每次特定的连接都可以更新
这样每个请求减少到只对特殊请求那么小(在static和dynamic表中的字段可不发送)
请求和响应头字段并没有什么改变, 只是所有的头字段必须小写命名, 请求行独立为
- :method
- :path
- scheme
- authority 这些伪请求头字段
升级到HTTP/2
因为HTTP/1.x还不能那么快推出舞台, 至少也还要10年, 所以HTTP/2要和HTTP/1.x共存, 那么HTTP/2服务器必须去发现和协商出最好的协议是什么, 所以HTTP/2定义了下列机制:
- 通过安全的连接(TLS和ALPN-Application Layer Protocol Negotiation)协商HTTP/2是否被支持
- 没有之前的信息直接升级纯文本连接到HTTP/2
- 有之前的信息发起纯文本HTTP/2连接
HTTP/2标准不需要TLS, 但是实践中需要可靠的部署新的协议, 所以TLS和ALPN成为了部署和协商的建议机制, 服务器和客户端协商协议版本, TLS建立握手连接, 两者相互不影响.在谷歌和火狐的浏览器中只有使用了安全连接才能启用HTTP/2
通过正常的不加密的信道建立HTTP/2连接仍然是可能的, 只是不被流行的浏览器支持, 需要额外的复杂度, 因为HTTP/1.x和HTTP/2都使用80端口, 在没有其他服务端支持的HTTP/2信息的情况下, 客户端可以使用 HTTP Upgrade字段来协商
GET /page HTTP/1.1
Host: server.example.com
Connection: Upgrade, HTTP2-Settings
Upgrade: h2c -------> 使用升级到HTTP/2头字段的初始化请求
HTTP2-Settings: (SETTINGS payload) --------> HTTP2设置, Base64URL编码
HTTP/1.1 200 OK -------> 服务器拒绝升级, 返回HTTP/1.1响应
Content-length: 243
Content-type: text/html
(... HTTP/1.1 response ...)
(or)
HTTP/1.1 101 Switching Protocols ------> 服务器接收升级, 转换到新的帧, 没有新的RRT发生
Connection: Upgrade
Upgrade: h2c
(... HTTP/2 response ...)
如果客户端选择记住HTTP/2的支持度, 通过DNS记录, 手动配置等, 而不是使用Update字段, 可以在一开始通过不加密信道直接发生HTTP/2帧, 坏的情况下如果服务器拒绝了可以再使用Upgrade流转换到TLS和ALPN协商上.
二进制帧的简介
之前已经讲过很多次二进制帧层了, HTTP/2就是因为这个二进制帧层所以才有了更好的网络传输性能. 一旦HTTP/2建立, 所有的帧都会共享一个共同的9字节(72Bit)的头, 包含帧的长度, 类型, flag的字段, 和31bits的流定义符

- 24位长度字段允许单个帧携带2^24字节的数据(~16MB)
- 8比特类型字段定义格式和帧的语法
- 8比特标志位字段
- 1比特保留字段位0
- 31比特为HTTP/2流定义唯一标识符
虽然这里定义最大可携带大约16MB的负载, 但是HTTP/2标准默认最大载荷为2^14bytes(16KB), 越大并不一定越好, 越小的帧可以更有效的利用多路复用和最小化线头阻塞
一旦frame的类型知道后, 帧就能被实例化和解析
- DATA
- 传输HTTP消息的body
- HEADERS
- 流的通信头字段
- PRIORITY
- 通信发送端建议流的优先级
- RST_STREAM
- 流的终止声明
- SETTINGS
- 连接的配置参数
- PUSH_PROMISE
- 相关资源即将推送的信号
- PING
- 衡量RTT和”liveness”检查
- GOAWAY
- 停止再当前连接中创建流
- WINDOW_UPDATE
- 针对个别流或个别连接以实现流量控制
- CONTINUATION
- 用于继续一系列头字段
以上所有都是升级到HTTP/2以后收发双端需要考虑的东西, 应用层时不会有任何影响的, 分帧层对应用来说是完全隐形的, 应用只做了两件事
- 初始化新的流
- 交换应用数据
那么请求或响应式如何转换成一个帧的呢?
发起新流
再任何应用数据被发送之前, 新的流必须被创建并且适当的请求元数据应该被发送比如之前说的流的权重, 依赖, 用来描述请求的HPACK-编码的请求头. 客户端通过 HEADERS 帧初始化 下图是Wireshark的一个解码后的HEADERS帧
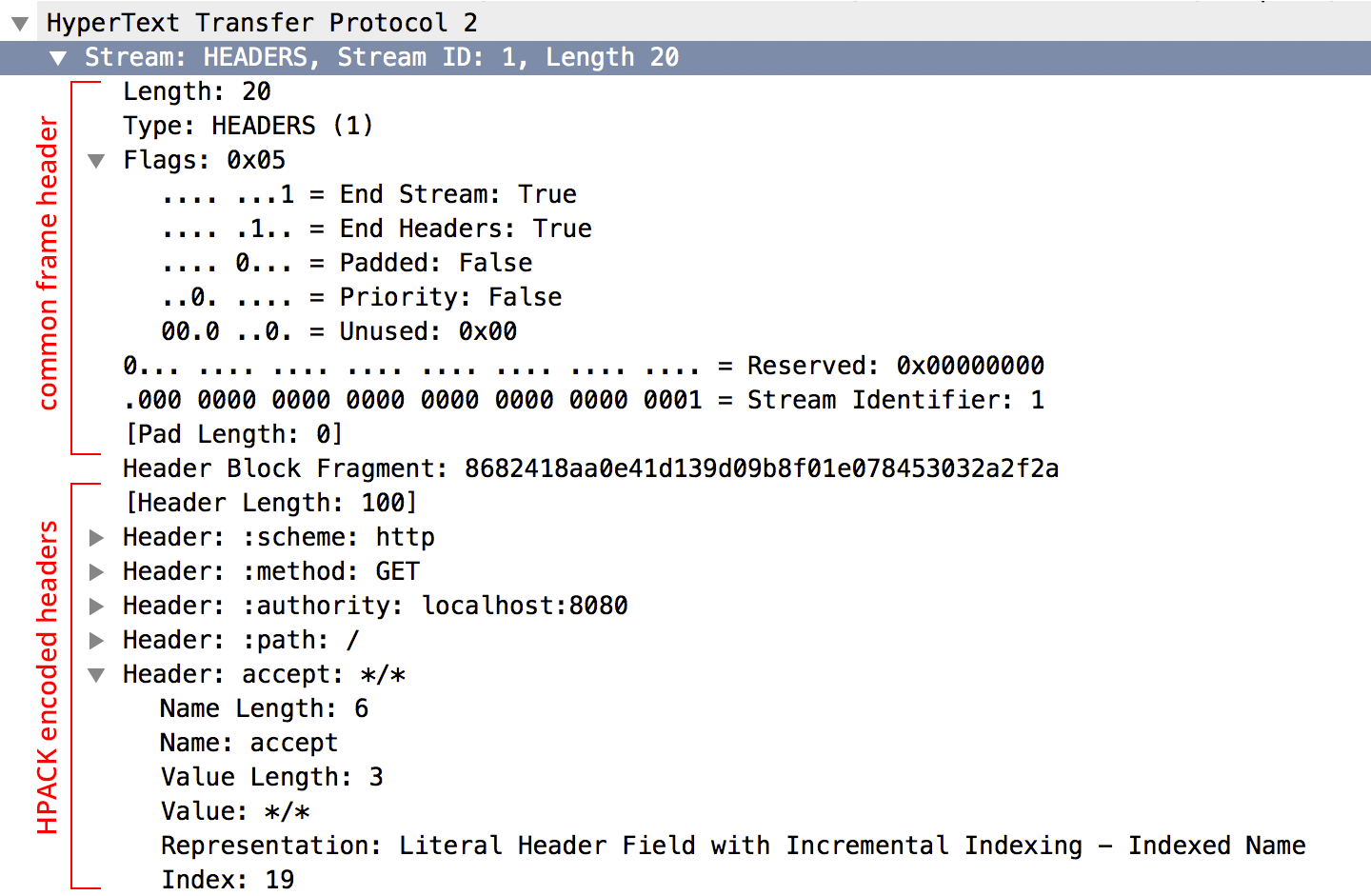
HEADERS和DATA帧通常分别发送, 流控制只对DATA帧生效, 其他的都有很高的优先级.
服务器端通过PUSH_PROMISE来新建流, 格式跟HEADERS差不多, 不过省略了stream依赖和优先级,因为是服务器完全控制数据的传输 那么双方都在发, 就有可能产生ID冲突, 所以计数器是是不同的, 客户端的流都是奇数, 服务端的都是偶数.所以在上图中可以看到设置为1也可以推断出为客户端流
发送数据
连接建立后就会发送 DATA 帧, 是负责发送应用载荷的, 该载荷可以分到多个DATA 帧中, 最后一个帧通过切换END_STREAM来表明消息传输完毕
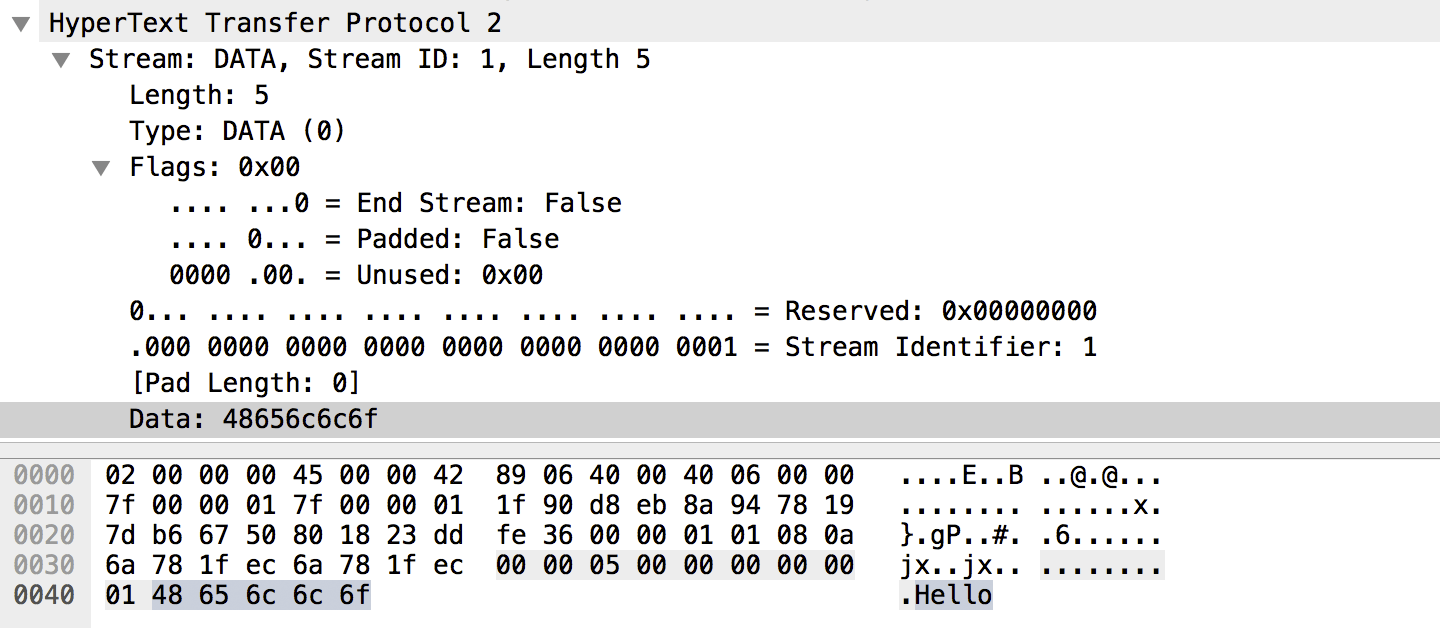
帧数据流分析:

- 三个流, ID分别为1,3,5, 奇数, 所以都是从客户端发起的流
- 没有服务端的流
- 服务端正在发送流1的DATA帧
- 服务端在stream1的DATA之间发送HEADERS和DATA帧, 复用响应行为
- 客户端正在传输tream5的DATA帧, 这个帧的HEADERS早已被发过
优化应用传输
高性能浏览器网络依赖网络技术的主机, 整体的应用性能表象为这些部分的总和

不能控制客户端和服务端的网络, 也不能控制客户端硬件和设备的配置, 但是其他的是掌握在手中的: 服务器的TCP和TLS优化, 以及一系列的针对不同物理层的应用优化, HTTP版本的使用和最佳应用实践.
优化物理和传输层
物理属性导致的性能限制
- 造成延迟的多个组件
- 高带宽和低延迟传输
- 延迟(而不是带宽)是性能瓶颈
不能让传输更快(接近光速), 所以应用所有可能的在传输和应用层可以减少每个包不必要的RRT, 请求, 最小化传输距离, 比如把server放到离client更近的地方
在无线网中, 延迟很高, 带宽也一直很珍贵, 在API层, 不管有线还是无线网络都是透明的. 仅仅优化资源下载处理传输的时机就能影响体验到的延迟, 电池寿命以及整体的用户体验
- 优化WIFI 网络
- 优化移动网络
从物理层上来, 必须保证每一个服务器配置最新的TCP和TLS的最佳实践
- TCP的优化
- TLS的优化
最后到达应用层, HTTP是很成功的协议
- 绕开HTTP/1.x的限制
- 利用HTTP/2
性能优化最佳实践
- 减少DNS查找
- 每次主机名的解析都需要网络往返
- 重用TCP连接
- Keep-Alive 三次握手和慢启动
- 最小化HTTP重定向
- 高延迟, 需要对不同的域进行DNS, TCP,LTS和请求响应往返
- 百到千毫秒级延迟
- 减少往返实践
- 服务器和用户近些
- 避免不必要的资源
- 再怎么优化都不如不传
HTTP提供了些额外机制
- 在客户端缓存资源
- 应用资源合理利用缓存策略避免相同数据的重复请求
- Cache-Control 头定义缓存时间(max-age)–>在这段时间内不用请求
- Last-Modified 和 ETag头提供验证机制–>验证是否资源更新
- 以上两者都必须提供
- 压缩资源
- 对每个传输资源使用最好的压缩策略
- Gzip对HTML, CSS, Javascript可压缩60%到80%
- 图片的压缩
- 不要携带额外的数据(EXIF)
- 尺寸缩小为显示的宽度大小(不要太大)
- 有损或无损压缩格式
- 避免不必要的请求字节
- 减少HTTP头数据(HTTP cookies)
- cookie的大小没有标准限值, 但是大多数浏览器为4KB
- 标准没有限制每个origin可以有多少个cookie, 所以也可将单个源的任意元数据通过分成多个cookie, 导致cookie的总大小为十几到千Kb
- HTTP/1.x中, 请求头包含cookie是没有被压缩的
- HTTP/2 请求头被HPACK压缩, 但是最小的cookie是在第一个请求中, 影响页面初始化加载
- 平行请求和响应处理
- 请求和响应排队的延迟不被注意但也影响重大,造成不必要的延迟
- 通过优化keeppalive超时重用TCP连接
- 使用HTTP/1.x的多连接特性, 当需要平行下载时
- 升级到HTTP/2, 开启多路复用
- 分配足够的服务器资源去并行处理请求
- 检查资源的瀑布图和服务器日志, 避免不必要的阻塞
- DOM, CSSOM, JS
- 代理或负载均衡容量不足,向应用服务器较复延迟(请求排队)
- 服务器不足, 执行慢
- 应用协议说明的优化
- HTTP/1.x
- 有限的平行机制(管道)
- bundle 资源于同一请求(雪碧图)
- split传输到多个domin
- 行内小资源
- HTTP/2在单个连接时性能更好
- HTTP/1.x最好的优化是迁移到HTTP/2中
- 不需要分Domain
- HTTP/2提供一个TLS合并机制允许客户端合并不同源的请求, 通过同一个连接发出, 必须满足下列条件
- 这些origins在同一个TLS证书下
- 比如example.com提供一个万用TLS证书, 对所有的子域名*.example.com都可用
- 这些origins解析到同一个IP地址
- static.example.com和example.com的IP地址一样
- 这些origins在同一个TLS证书下
- HTTP/2提供一个TLS合并机制允许客户端合并不同源的请求, 通过同一个连接发出, 必须满足下列条件
- 最小化拼接和雪碧图
- bundle资源可能导致不必要的数据传输, 用户可能在某个特定页面并不需哟所有的资源
- bundle资源可能导致昂贵的缓存失效, 一个小的改动都需要整个bundle的重新获取
- bundle的资源可能会延迟执行, 许多内容类型在响应整个完成前不能被执行和应用
- bundle资源可能需要额外的在构建时的配置,生成相关bundle也需要花更多的时间
- bundle资源可能提供更好的压缩, 如果资源包含相同的类型
- 并不是说不能拼接资源和不适用雪碧图
- 包含类似文件的数据可以在bundle时更好的压缩
- 每个资源请求开销, 在从缓存中读取(I/O请求)和从网络中获取(I/O请求, on-the-wire元数据, 和服务器处理)
- 通过服务器推送减少来回时间
- 以前用行内数据(比如包含在HTML文档中的图片)
- 由服务端发出, 但是客户端可以控制怎样以及哪里去使用推送的数据通过最大push流数量和每个流的最大数据限制或者彻底禁用
- 严格遵从同源策略, 也就是HTTP/1.x中的分源在这里是行不通的
- 服务端推送的响应处理跟客户端请求响应处理一样, 意味着可以被多个页面和导航重用
- HTTP/1.x
- 测试HTTP/2 服务质量
- 因为网络的优化, 客户端更加依赖于对服务器的信任, 信任服务器会按照客户端的优先级传输
- 如果客户端不关任何的优先级信息?
- 在客户端产生不必要的处理延迟, 阻塞浏览器渲染
- 但是严格以来顺序传输流又会陷入之前的线头阻塞问题
- 服务器应优先处理高优先级的流, 但是也会在高优先级流被阻塞的情况下交叉低优先级或不相互依赖的流(反之客户端都会再根据流的优先级顺序或id进行排序)